
While Text-to-Image (T2I) diffusion models excel at generating visually appealing images of individual instances, they struggle to accurately position and control the features generation of multiple instances. The Layout-to-Image (L2I) task was introduced to address the positioning challenges by incorporating bounding boxes as spatial control signals, but it still falls short in generating precise instance features. In response, we propose the Instance Feature Generation (IFG) task, which aims to ensure both positional accuracy and feature fidelity in generated instances. To address the IFG task, we introduce the Instance Feature Adapter (IFAdapter). The IFAdapter enhances feature depiction by incorporating additional appearance tokens and utilizing an Instance Semantic Map to align instance-level features with spatial locations. The IFAdapter guides the diffusion process in a plug-and-play module, making it adaptable to various community models. For evaluation, we contribute an IFG benchmark and develop a verification pipeline to objectively compare models’ abilities to generate instances with accurate positioning and features. Experimental results demonstrate that IFAdapter outperforms other models in both quantitative and qualitative evaluations.
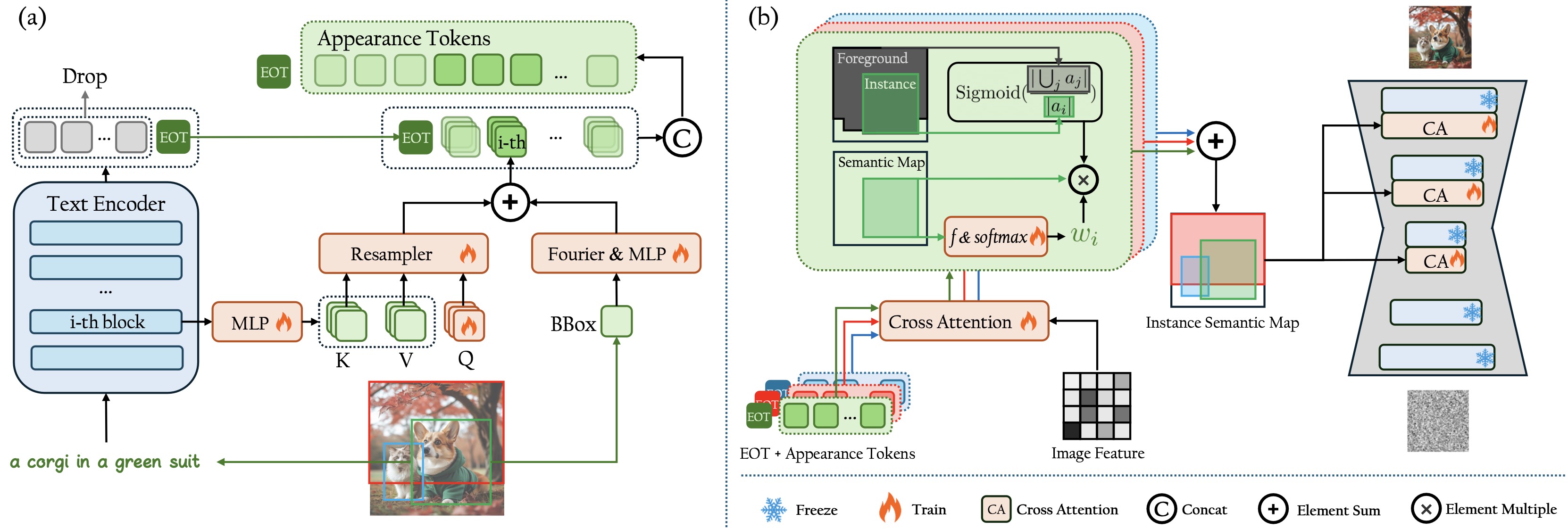
Structure of proposed IFAdapter. (a) The generation process of Appearance Tokens. For simplicity, we use the generation process of one instance (the corgi) as example. (b) The construction process of the Instance Semantic Map.

Qualitative results. We compare the models' ability to generate instances with different types of features, including mixed colors, varied materials, and intricate textures.

The IFAdapter can seamlessly integrate with community diffusion models.
@article{wu2024ifadapter,
title={IFAdapter: Instance Feature Control for Grounded Text-to-Image Generation},
author={Yinwei Wu and Xianpan Zhou and Bing Ma and Xuefeng Su and Kai Ma and Xinchao Wang},
journal={arXiv preprint arXiv:2409.08240},
year={2024}
}